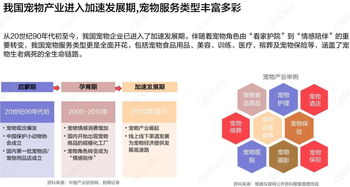
旌陽區(qū)杯總館日用品店是一家專注于日用品銷售的零售商店,致力于為當(dāng)?shù)鼐用裉峁┍憬荨?yōu)質(zhì)的生活服務(wù)。店鋪位于旌陽區(qū)交通便利的杯總館區(qū)域,覆蓋廣泛的日用品品類,包括清潔用品、個(gè)人護(hù)理產(chǎn)品、廚房用具、家居裝飾等。我們以實(shí)惠的價(jià)格、豐富的選擇和貼心的服務(wù),贏得了眾多顧客的信賴與好評。
店內(nèi)商品種類齊全,從日常必需的洗衣液、洗發(fā)水到環(huán)保家居用品,無不精心挑選,確保質(zhì)量可靠。我們還定期推出促銷活動(dòng),幫助顧客以更低的成本提升生活品質(zhì)。店員團(tuán)隊(duì)經(jīng)驗(yàn)豐富,能為顧客提供專業(yè)的選購建議,讓購物過程更加輕松愉快。
作為旌陽區(qū)社區(qū)的重要一員,杯總館日用品店不僅關(guān)注商業(yè)運(yùn)營,還積極參與社區(qū)活動(dòng),支持本地經(jīng)濟(jì)發(fā)展。我們相信,通過持續(xù)優(yōu)化產(chǎn)品和服務(wù),能夠成為您生活中可靠的伙伴。歡迎廣大顧客光臨惠顧,體驗(yàn)一站式日用品購物的便利與實(shí)惠!